P-EAGLE: Acelere la Inferencia de LLMs con Decodificación Paralela
P-EAGLE es una solución innovadora que optimiza la inferencia de Large Language Models mediante decodificación paralela, logrando mejoras significativas de velocidad de hasta 1.69x en comparación con EAGLE-3 en escenarios reales.
P-EAGLE: Acelere la Inferencia de LLMs con Decodificación Paralela
Los Large Language Models (LLMs) están transformando diversas áreas, desde la atención al cliente hasta la creación de contenido. Sin embargo, la inferencia – el proceso de generar respuestas a partir de estos modelos – puede ser un cuello de botella, especialmente en aplicaciones que exigen baja latencia. P-EAGLE surge como una solución innovadora, optimizando la inferencia de LLMs a través de un enfoque de decodificación paralela, elevando el rendimiento a un nuevo nivel.
15 de marzo de 2026
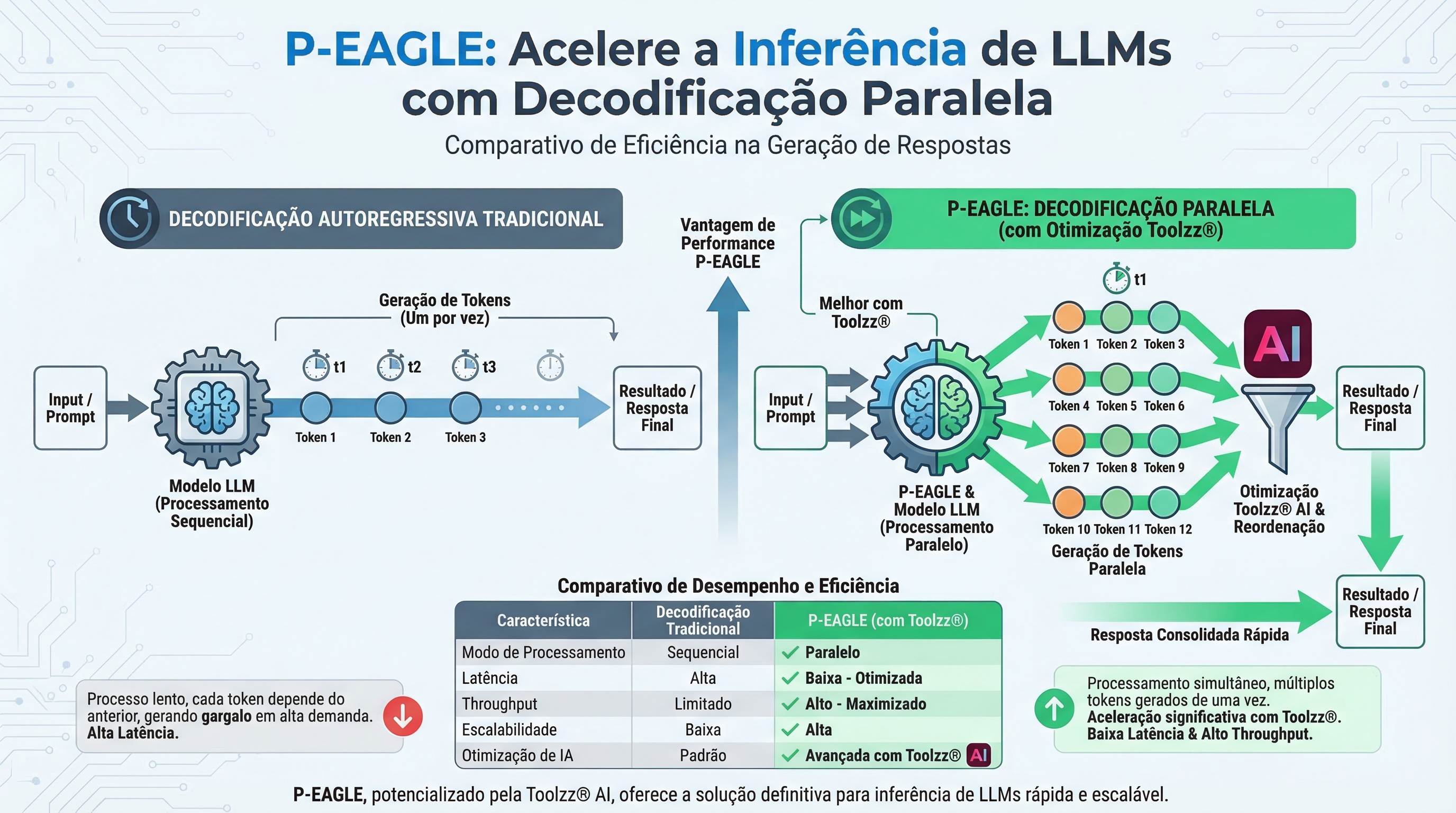

El Desafío de la Inferencia en LLMs
La inferencia de LLMs involucra la generación secuencial de tokens (palabras o partes de palabras). Los métodos tradicionales, como la decodificación autorregresiva, generan cada token uno tras otro, lo que puede ser lento en modelos grandes y con secuencias largas. EAGLE, un método de decodificación especulativa, ya representó un avance significativo, pero aún presentaba limitaciones con la generación autorregresiva de drafts (borradores), impactando la velocidad en tareas que demandan alta especulación.
Presentando P-EAGLE: Decodificación Paralela para Velocidad Mejorada
P-EAGLE (Parallel-EAGLE) resuelve el problema de EAGLE al introducir la generación paralela de drafts. En lugar de generar los tokens de draft secuencialmente, P-EAGLE genera todos los K tokens simultáneamente en una única pasada, eliminando el cuello de botella de la generación autorregresiva. Esto resulta en un aumento significativo en la velocidad de inferencia, especialmente en GPUs modernas como la NVIDIA B200, con ganancias de hasta 1.69x en relación con EAGLE-3 en escenarios reales.
Si está buscando optimizar el rendimiento de sus LLMs, conozca Toolzz AI y descubra cómo podemos ayudar.
¿Cómo Funciona P-EAGLE?
P-EAGLE opera en dos etapas principales:
Prefilling: El modelo principal procesa el prompt y genera el token inicial, capturando los hidden states (estados ocultos) que representan el conocimiento del modelo en cada posición.
P-EAGLE Drafter: El drafter utiliza los hidden states capturados en la etapa anterior para generar K tokens de draft en paralelo. Para posiciones en el prompt, combina el embedding del token con el hidden state correspondiente. Para posiciones futuras, utiliza embeddings de máscara y hidden states compartidos para llenar los vacíos.
Esta arquitectura permite que P-EAGLE prediga varios tokens simultáneamente, acelerando drásticamente el proceso de inferencia.
Entrenamiento de P-EAGLE para Secuencias Largas
Los modelos de lenguaje modernos frecuentemente manejan secuencias largas, lo que presenta desafíos de memoria durante el entrenamiento del drafter. P-EAGLE introduce un algoritmo de particionamiento de secuencia que divide la secuencia en bloques contiguos, manteniendo las dependencias de atención entre los bloques y acumulando gradientes en toda la secuencia. Esto permite entrenar P-EAGLE en secuencias largas sin exceder los límites de memoria.

Implementando P-EAGLE con vLLM
La integración de P-EAGLE en vLLM es simplificada. Basta con agregar "parallel_drafting": true a la configuración de SpeculativeConfig. Los modelos preentrenados P-EAGLE ya están disponibles en HuggingFace para GPT-OSS 120B, GPT-OSS 20B y Qwen3-Coder 30B, permitiendo que comience a beneficiarse de las ventajas de P-EAGLE inmediatamente.
¿Quiere experimentar el poder de la inferencia acelerada? Solicite una demostración de Toolzz AI y vea cómo podemos optimizar sus LLMs.
El Impacto de P-EAGLE en Aplicaciones Prácticas
P-EAGLE tiene el potencial de transformar una variedad de aplicaciones que dependen de LLMs, incluyendo:
- Chatbots: Respuestas más rápidas e interacciones más fluidas.
- Asistentes Virtuales: Mejor capacidad de respuesta y procesamiento de solicitudes complejas.
- Generación de Contenido: Creación más rápida de artículos, resúmenes y otros tipos de contenido.
- Análisis de Sentimiento: Procesamiento más rápido de grandes volúmenes de texto para análisis de sentimiento en tiempo real.
El Futuro de la Inferencia de LLMs con Toolzz
La optimización de la inferencia de LLMs es fundamental para desbloquear todo el potencial de estas tecnologías. Toolzz está a la vanguardia de esta evolución, y P-EAGLE representa un paso importante en esa dirección. Con Toolzz AI, puede aprovechar el poder de LLMs optimizados, como P-EAGLE, para crear soluciones de IA personalizadas y escalables. Explore nuestros agentes de IA y descubra cómo podemos ayudarlo a transformar sus negocios con la inteligencia artificial. Si busca maximizar el rendimiento y reducir la latencia en sus aplicaciones de LLM, Toolzz es su socio ideal. ¡Pruebe Toolzz AI hoy mismo y vea la diferencia!














