Reduzca Costos con IA: 10 Estrategias para Optimizar el Uso de Tokens
Guía completa con 10 estrategias prácticas para reducir costos de inteligencia artificial mediante la optimización del uso de tokens, mejorando la eficiencia y escalabilidad de tus sistemas de IA.

Reduzca Costos con IA: 10 Estrategias para Optimizar el Uso de Tokens
17 de marzo de 2026
A medida que la inteligencia artificial se vuelve cada vez más presente en nuestras aplicaciones, el control de costos asociados a su uso se vuelve crucial. Uno de los principales componentes de estos costos es el consumo de tokens, unidades de datos procesadas por los modelos de lenguaje. Optimizar el uso de tokens no solo reduce gastos, sino que también mejora el rendimiento y la escalabilidad de sus sistemas de IA.
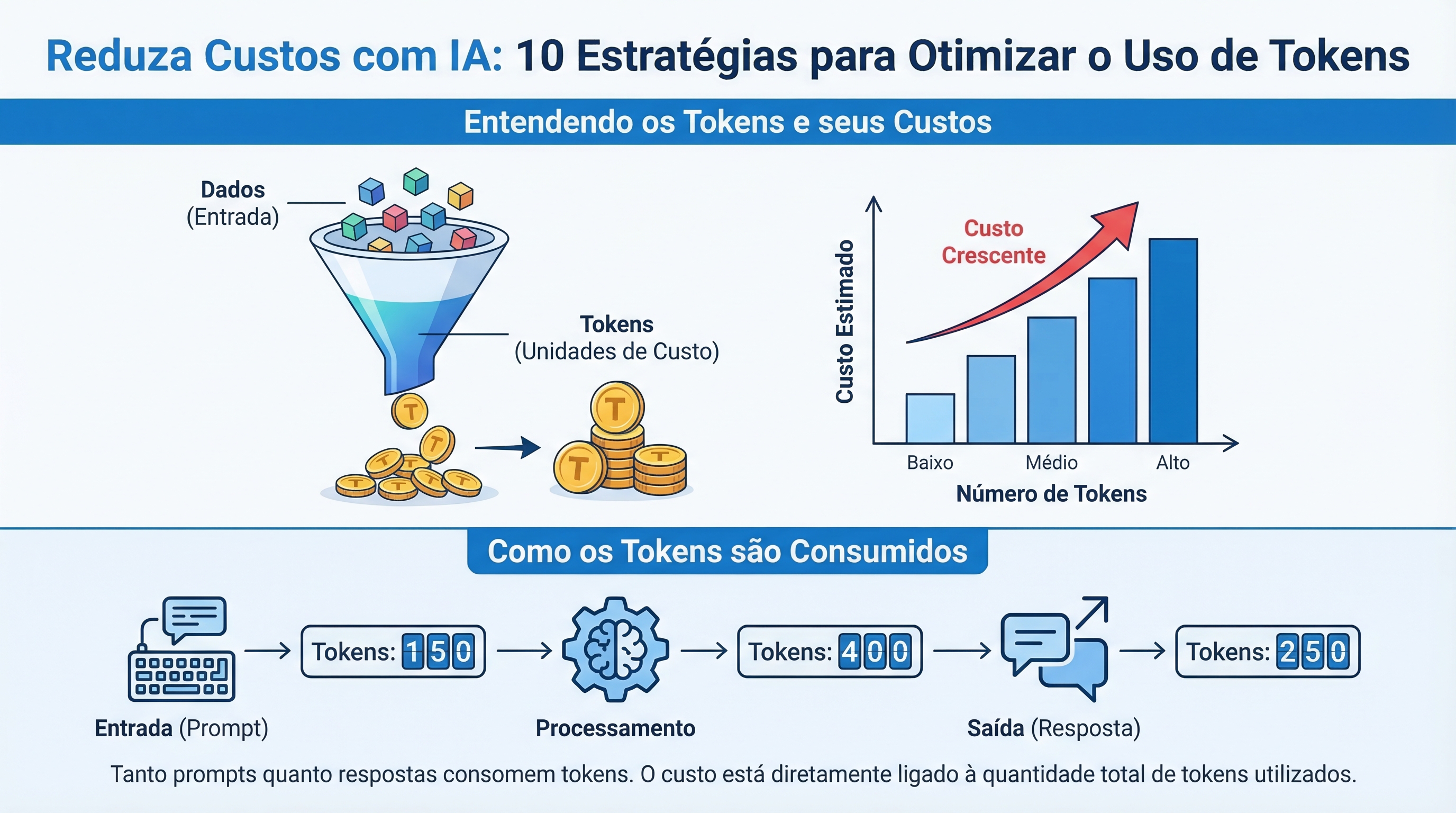
Entendiendo los Tokens y sus Costos
Un token representa la unidad más pequeña de información que un modelo de IA procesa. Tanto la entrada (prompt) como la salida (respuesta) de un modelo consumen tokens. El costo del uso de IA está directamente vinculado a la cantidad de tokens utilizados. Entender cómo se cuentan los tokens y cómo reducir su consumo es fundamental para optimizar sus gastos.
1. Use el Bloque de Instrucciones del Sistema
Una práctica común es incluir instrucciones sobre el comportamiento deseado del modelo directamente en el prompt del usuario. Sin embargo, estas instrucciones se cuentan como tokens en cada solicitud. Al usar el "bloque de instrucciones del sistema", usted define el comportamiento del modelo una única vez, evitando la repetición de estas instrucciones en cada prompt. Esto reduce significativamente el consumo de tokens, especialmente en conversaciones largas o interacciones frecuentes.
2. Implemente Secuencias de Parada
Los modelos de lenguaje pueden generar respuestas excesivamente largas o incluir información innecesaria. Definir "secuencias de parada" instruye al modelo a interrumpir la generación de texto al encontrar una determinada secuencia de caracteres. Esto evita el consumo de tokens con información irrelevante y garantiza respuestas más concisas y eficientes.
3. Ajuste la Resolución de Medios
Al trabajar con imágenes u otros tipos de medios, la resolución impacta directamente el número de tokens consumidos. Si la alta resolución no es esencial para la tarea en cuestión, reducir la resolución del medio puede disminuir significativamente el uso de tokens, sin comprometer la calidad del resultado.
4. Limite o Deshabilite el Pensamiento
En algunas aplicaciones, es posible limitar o deshabilitar la capacidad del modelo de "pensar" o generar explicaciones detalladas. Esto puede ser útil cuando solo se necesita la respuesta final, reduciendo el consumo de tokens con explicaciones innecesarias. La Toolzz AI permite configurar niveles de razonamiento para sus agentes, optimizando la eficiencia en diferentes escenarios.
5. Utilice Caché de Contexto
En interacciones largas, el modelo necesita mantener el contexto de la conversación para generar respuestas coherentes. Almacenar en caché la información relevante del contexto puede evitar la repetición de información en el prompt, reduciendo el consumo de tokens.
6. Explore la Notación TOON (Token-Oriented Object Notation)
TOON es un formato de datos diseñado para optimizar la comunicación con modelos de lenguaje, minimizando el número de tokens utilizados para representar información compleja. Al estructurar sus datos en TOON, puede reducir significativamente el consumo de tokens en comparación con formatos tradicionales como JSON.
7. Enrutamiento Inteligente de Modelos
No todas las tareas requieren el modelo de lenguaje más poderoso y costoso. Implementar un sistema de enrutamiento inteligente que dirige cada tarea al modelo más adecuado puede optimizar costos y rendimiento. Utilice modelos más ligeros para tareas simples y reserve los modelos más avanzados para tareas complejas.
¿Quiere optimizar sus costos con IA?
Descubra los planes de Toolzz AI8. Retención Selectiva
La retención del historial de conversaciones es crucial para mantener el contexto. Sin embargo, mantener todo el historial puede consumir muchos tokens. Implemente una estrategia de retención selectiva, almacenando solo la información más relevante del historial, descartando información innecesaria.
9. Defina un Esquema de Respuesta
Al definir un esquema de respuesta específico, usted instruye al modelo a generar respuestas en un formato predefinido, reduciendo la variabilidad y el tamaño de las respuestas. Esto puede disminuir el consumo de tokens y facilitar el procesamiento de las respuestas.
10. Use Optimizadores de Prompt
Existen herramientas y técnicas para optimizar sus prompts, eliminando información redundante, simplificando el lenguaje y garantizando que el prompt sea claro y conciso. Plataformas como Toolzz ofrecen recursos avanzados de optimización de prompts, ayudándole a obtener el máximo de sus modelos de lenguaje con el mínimo de tokens.
¡Optimice sus prompts y reduzca costos! Descubra cómo Toolzz AI puede ayudarle a maximizar la eficiencia de sus modelos de lenguaje.
Al implementar estas estrategias, puede reducir significativamente los costos asociados al uso de IA, mejorando el rendimiento y la escalabilidad de sus aplicaciones. Optimizar el uso de tokens no es solo una cuestión de economía, sino también de responsabilidad y eficiencia.
Con Toolzz LXP, puede crear entrenamientos personalizados para su equipo sobre optimización de costos con IA, garantizando que todos estén alineados con las mejores prácticas. Además, nuestros Agentes AI pueden automatizar tareas repetitivas y optimizar procesos, liberando a su equipo para concentrarse en actividades de mayor valor.
Vea qué fácil es crear su IA
Haga clic en la flecha abajo para comenzar una demostración interactiva de cómo crear su propia IA.



















