Resumption Tokens and IDs for LLM Streaming: Intelligent Reconnection
An in-depth guide on implementing resumption tokens and event IDs for LLM streaming, ensuring seamless reconnection and uninterrupted user experiences during network interruptions.

March 15, 2026
Resumption Tokens and IDs for LLM Streaming: Intelligent Reconnection
A connection interruption during the streaming of responses from language models (LLM) can be frustrating and costly, requiring the process to restart from scratch. Resumption tokens and last event IDs emerge as solutions to ensure streaming continuity, allowing clients to resume exactly where they left off, without data loss or the need to repeat requests. These mechanisms are crucial for maintaining a smooth and efficient user experience, especially in applications that depend on long and complex responses.
How Resumption Tokens Work
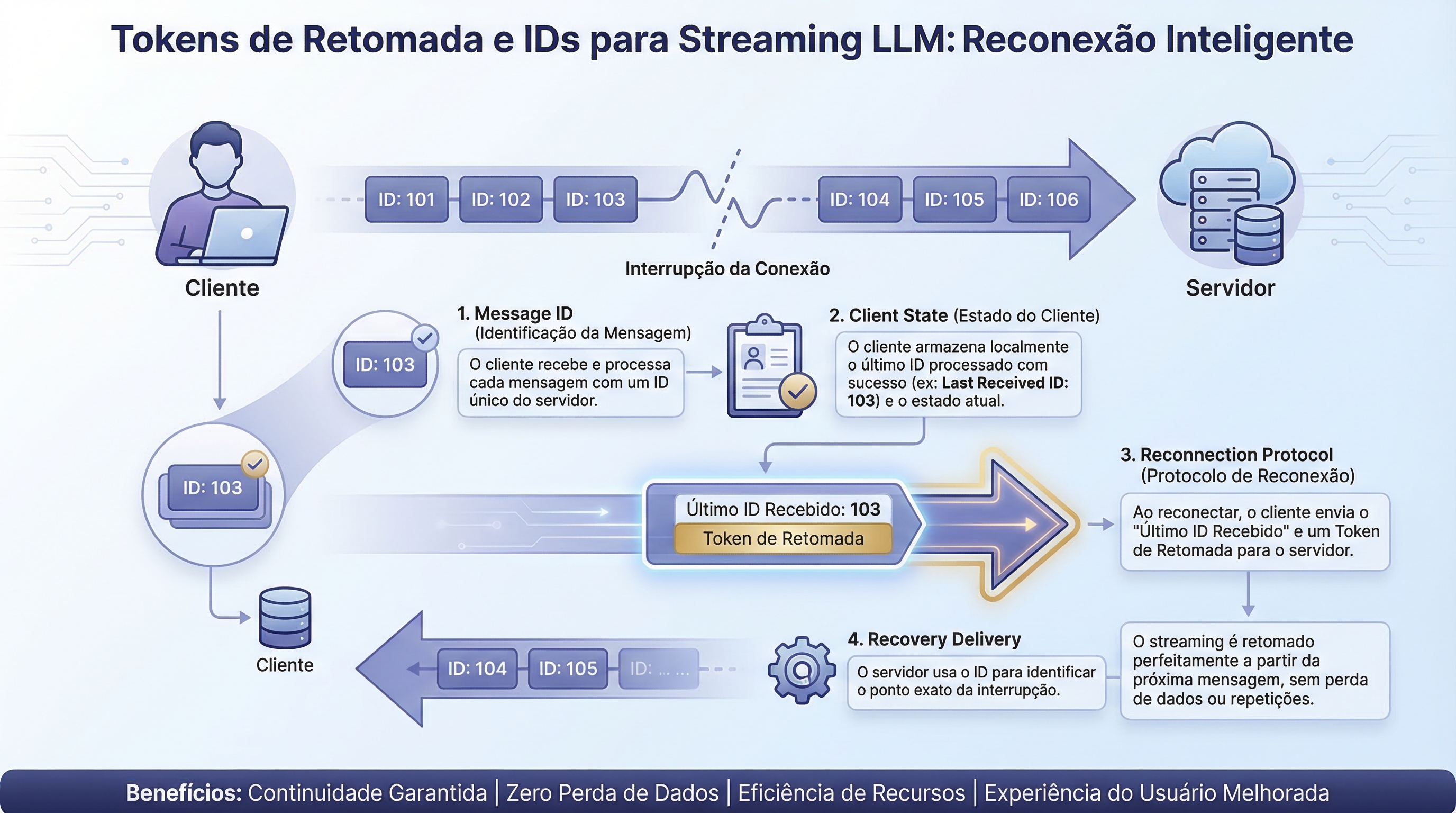
Streaming resumption involves four main components:
- Message Identifiers: Each token or message receives a sequential ID, monotonically increasing.
- Client State: The client tracks the ID of the last successfully received message. This state needs to be persistent, especially on mobile devices.
- Reconnection Protocol: After a connection drop, the client presents the last received ID. The server responds with all subsequent messages.
- Recovery Delivery: The client receives the lost messages in order before resuming live streaming, ensuring a smooth transition.
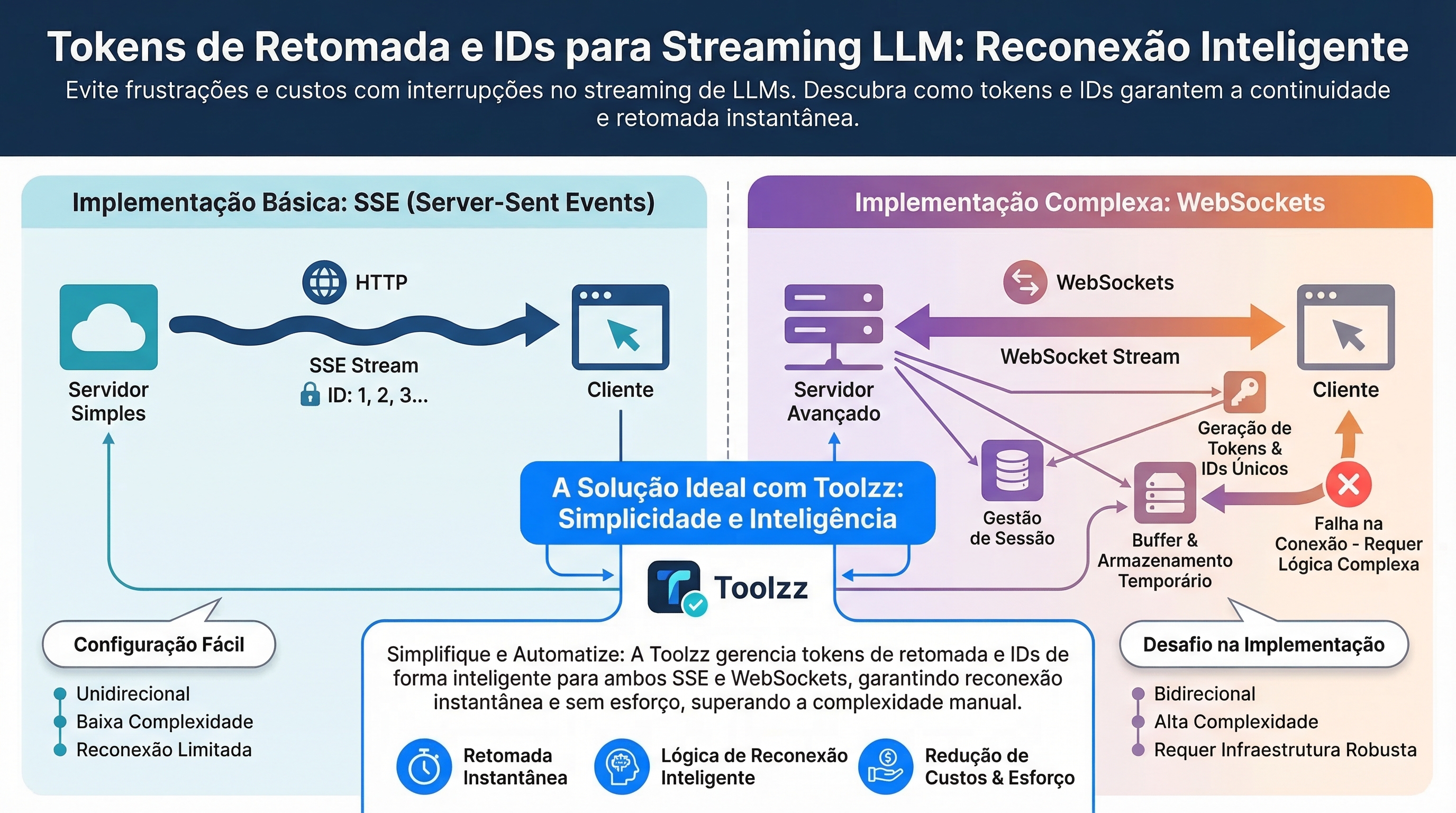
Server-Sent Events (SSE) and Last-Event-ID
Server-Sent Events (SSE) implements resumption natively. When an SSE connection is interrupted, the browser automatically includes a Last-Event-ID header on reconnection. The server uses this ID to resume streaming from the correct point. However, SSE is unidirectional and HTTP-only, which limits its ability to handle bidirectional messages or multi-device scenarios.
Resumption in WebSockets
WebSockets, unlike SSE, do not have built-in resumption semantics. Implementing resumption in WebSockets requires building all the logic, including:
- Generation and storage of session IDs.
- Sequential assignment of message IDs.
- Server logic to fetch sessions, replay history, and transition to live streaming.
- Buffer management for unconfirmed messages.
- Cleanup logic for expired sessions.
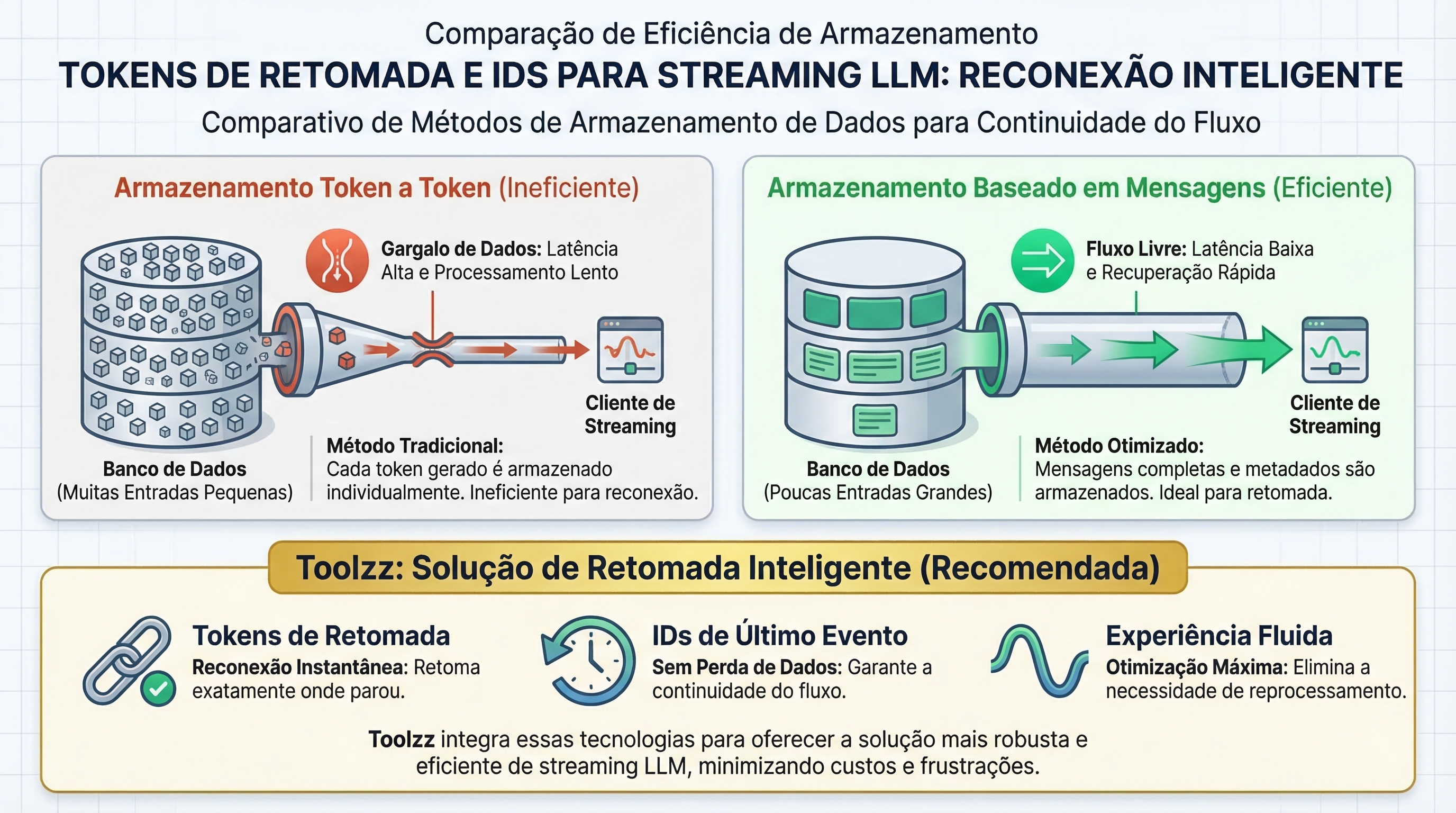
Storage and Recovery Challenges
Storing tokens at a granular level (token by token) can become a performance bottleneck. A 500-word response can generate 625 tokens, requiring the retrieval of 625 records to reconstruct the response. A more efficient approach is to treat each AI response as a single logical message, appending the tokens to it. This drastically reduces the number of records to be managed.
Are you looking to optimize LLM usage in your company? Learn about Toolzz AI and discover how we can help you.
Duplication and Gaps: Critical Failures
Duplications occur when the connection drops after the client receives a message, but before the server receives confirmation. On reconnection, the server may resend the same message. The solution is to use message IDs as deduplication keys on the client.
Gaps occur when sequential IDs arrive out of order or don't arrive. Without gap detection, the client may render an incomplete response. Gap detection requires logic to request missing messages and handle the inability to recover them.
Implications of Distributed Implementation
In an implementation with multiple servers, a client may reconnect to a different instance than the original. This requires a strategy for:
Routing reconnections to the original instance (which can create hotspots).
Storing session state in a shared infrastructure (such as Redis), accessible to all instances.
The Multi-Device Gap
Multi-device continuity requires a different architecture. When state resides in the connection or server memory, switching devices loses context. The solution is to decouple state from connections, storing the conversation in a channel or persistent storage. Devices subscribe and retrieve history, rather than resuming a connection.
When Streaming Resumption is Essential
Streaming resumption is crucial in scenarios such as:
- Mobile clients with frequent network handoffs.
- Long responses, with a high probability of transient failures.
- Multi-device usage.
- Multi-agent systems, where multiple agents publish updates to a shared channel.
Toolzz Voice: Ensure Continuity in Voice Interactions
Implementing resumption tokens and event IDs can be complex, requiring time and expertise to handle all nuances and failure scenarios. For companies seeking a robust and efficient solution for voice agents, Toolzz Voice offers guaranteed continuity in interactions, even under unstable network conditions. With Toolzz, you can focus on creating high-quality conversational experiences, without worrying about the technical details of streaming resumption.
Additionally, Toolzz AI offers a complete range of custom AI agents for various needs, from Sales AI to Support AI, seamlessly integrating with Toolzz Voice and other platform solutions. Discover how Toolzz can transform your company's communication. Schedule a demo today.
Streaming resumption is fundamental to ensuring a consistent and reliable user experience in applications that use LLMs. Although implementation can be challenging, the benefits in terms of user retention and cost reduction make it a valuable investment. Toolzz offers solutions that simplify the implementation and management of AI agents, allowing you to focus on what really matters: creating value for your customers.


















