P-EAGLE: Accelerate LLM Inference with Parallel Decoding
P-EAGLE is an innovative solution that optimizes LLM inference through a parallel decoding approach, achieving up to 1.69x speedup over EAGLE-3 by generating draft tokens simultaneously instead of sequentially.
P-EAGLE: Accelerate LLM Inference with Parallel Decoding
Large Language Models (LLMs) are transforming various areas, from customer service to content creation. However, inference – the process of generating responses from these models – can be a bottleneck, especially in applications that require low latency. P-EAGLE emerges as an innovative solution, optimizing LLM inference through a parallel decoding approach, elevating performance to a new level.
March 15, 2026
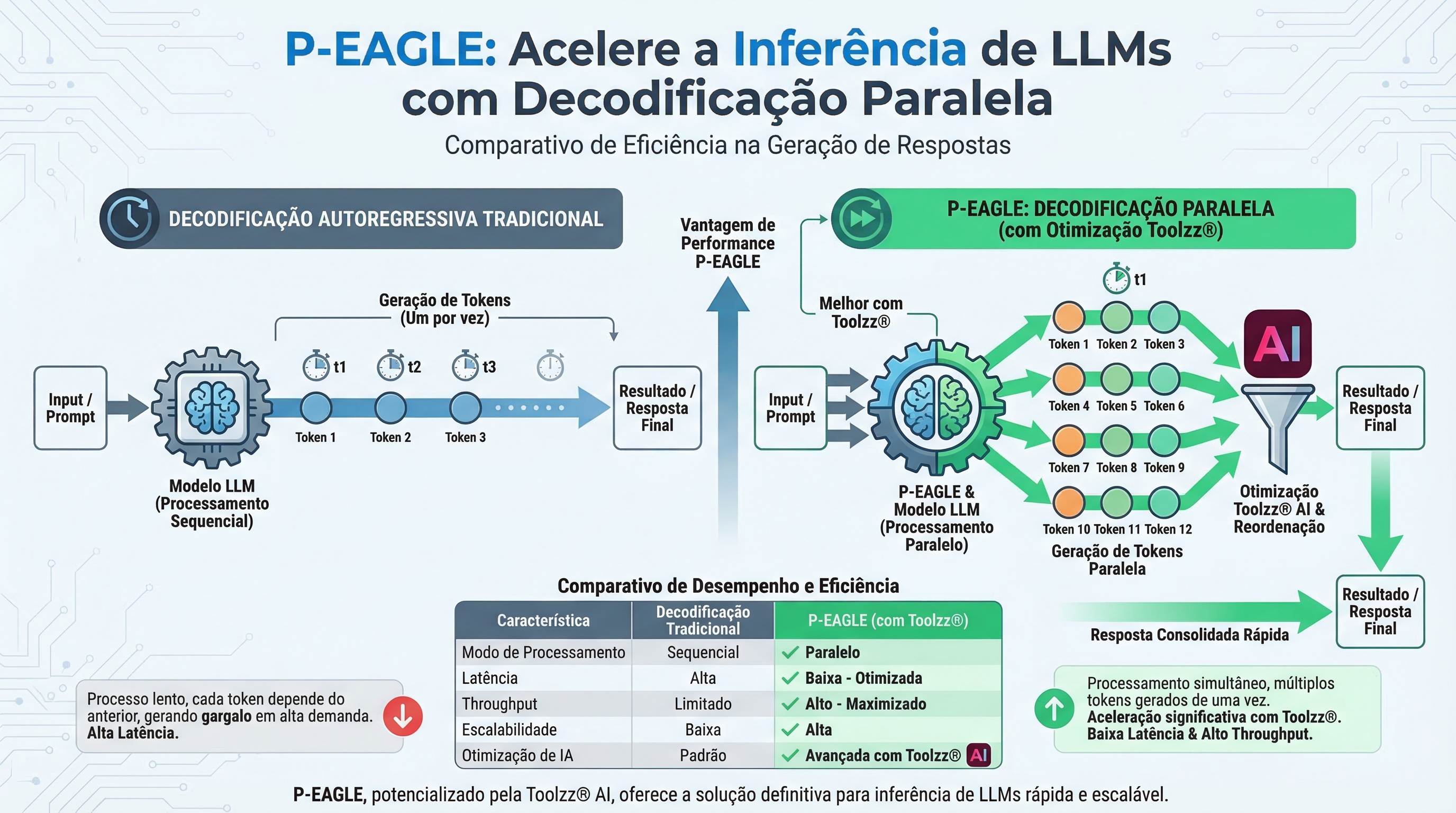

The Challenge of LLM Inference
LLM inference involves the sequential generation of tokens (words or parts of words). Traditional methods, such as autoregressive decoding, generate each token one after another, which can be slow in large models and with long sequences. EAGLE, a speculative decoding method, already represented a significant advancement, but still had limitations with autoregressive generation of drafts, impacting speed in tasks that demand high speculation.
Introducing P-EAGLE: Parallel Decoding for Enhanced Speed
P-EAGLE (Parallel-EAGLE) solves EAGLE's problem by introducing parallel draft generation. Instead of generating draft tokens sequentially, P-EAGLE generates all K tokens simultaneously in a single pass, eliminating the bottleneck of autoregressive generation. This results in a significant increase in inference speed, especially on modern GPUs like the NVIDIA B200, with gains of up to 1.69x over EAGLE-3 in real-world scenarios.
If you're looking to optimize your LLMs' performance, discover Toolzz AI and find out how we can help.
How Does P-EAGLE Work?
P-EAGLE operates in two main stages:
Prefilling: The main model processes the prompt and generates the initial token, capturing the hidden states that represent the model's knowledge at each position.
P-EAGLE Drafter: The drafter uses the hidden states captured in the previous stage to generate K draft tokens in parallel. For positions in the prompt, it combines the token embedding with the corresponding hidden state. For future positions, it uses mask embeddings and shared hidden states to fill the gaps.
This architecture allows P-EAGLE to predict multiple tokens simultaneously, drastically accelerating the inference process.
Training P-EAGLE for Long Sequences
Modern language models frequently handle long sequences, which presents memory challenges during drafter training. P-EAGLE introduces a sequence partitioning algorithm that divides the sequence into contiguous blocks, maintaining attention dependencies between blocks and accumulating gradients across the entire sequence. This allows training P-EAGLE on long sequences without exceeding memory limits.

Implementing P-EAGLE with vLLM
Integrating P-EAGLE into vLLM is simplified. Just add "parallel_drafting": true to the SpeculativeConfig configuration. Pre-trained P-EAGLE models are already available on HuggingFace for GPT-OSS 120B, GPT-OSS 20B, and Qwen3-Coder 30B, allowing you to start benefiting from P-EAGLE's advantages immediately.
Want to experience the power of accelerated inference? Request a Toolzz AI demo and see how we can optimize your LLMs.
The Impact of P-EAGLE on Practical Applications
P-EAGLE has the potential to transform a variety of applications that depend on LLMs, including:
- Chatbots: Faster responses and more fluid interactions.
- Virtual Assistants: Better responsiveness and processing of complex requests.
- Content Generation: Faster creation of articles, summaries, and other types of content.
- Sentiment Analysis: Faster processing of large volumes of text for real-time sentiment analysis.
The Future of LLM Inference with Toolzz
Optimizing LLM inference is fundamental to unlocking the full potential of these technologies. Toolzz is at the forefront of this evolution, and P-EAGLE represents an important step in this direction. With Toolzz AI, you can leverage the power of optimized LLMs, like P-EAGLE, to create customized and scalable AI solutions. Explore our AI agents and discover how we can help you transform your business with artificial intelligence. If you seek to maximize performance and reduce latency in your LLM applications, Toolzz is your ideal partner. Try Toolzz AI today and see the difference!














