Reduce AI Costs: 10 Strategies to Optimize Token Usage
A comprehensive guide to optimizing AI costs by implementing strategic token management techniques. Learn 10 practical strategies to reduce token consumption while maintaining performance and scalability in your AI applications.

Reduce AI Costs: 10 Strategies to Optimize Token Usage
March 17, 2026
As artificial intelligence becomes increasingly present in our applications, controlling the costs associated with its use becomes crucial. One of the main components of these costs is token consumption, the units of data processed by language models. Optimizing token usage not only reduces expenses but also improves the performance and scalability of your AI systems.
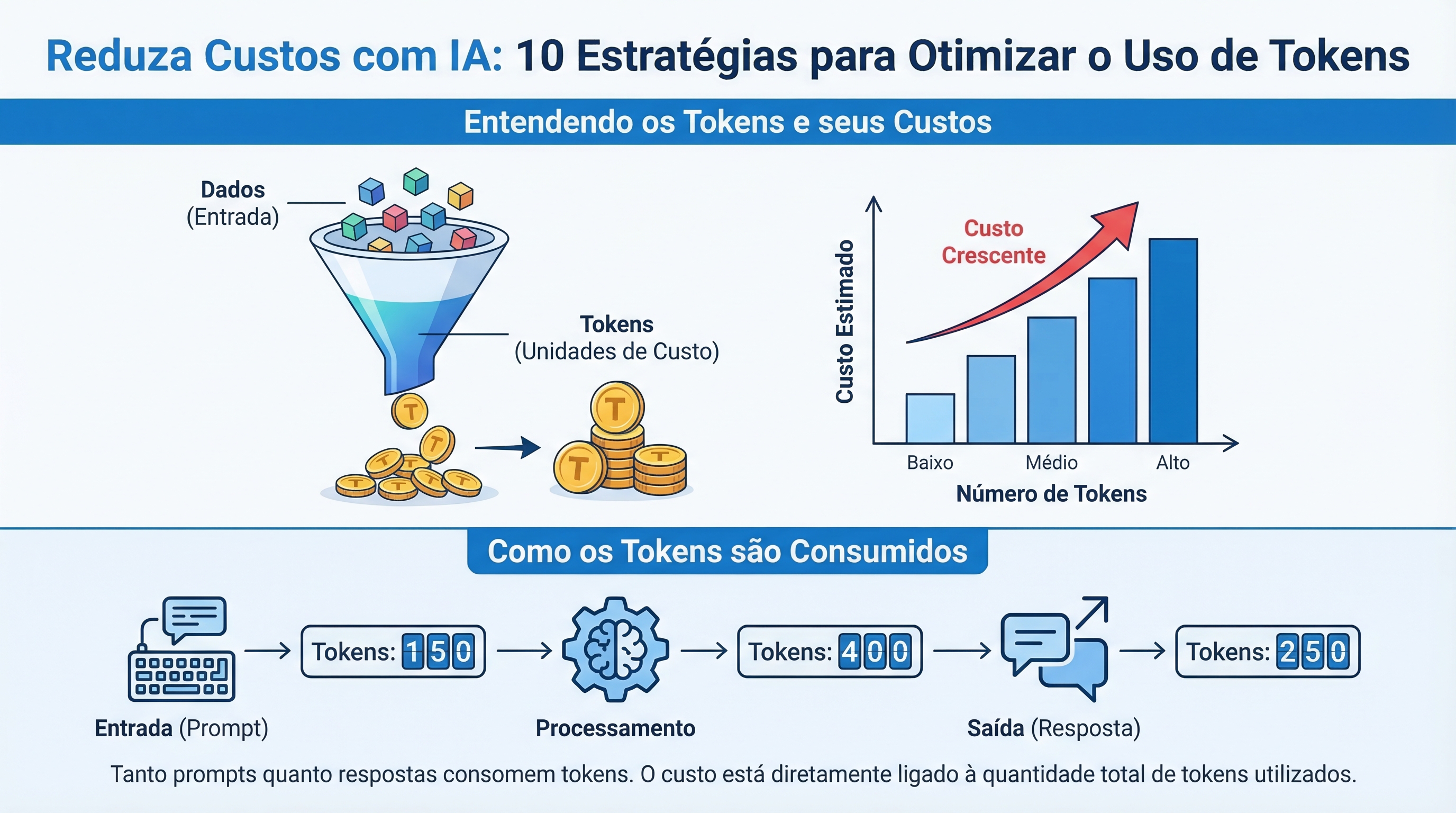
Understanding Tokens and Their Costs
A token represents the smallest unit of information that an AI model processes. Both the input (prompt) and output (response) of a model consume tokens. The cost of using AI is directly linked to the number of tokens used. Understanding how tokens are counted and how to reduce their consumption is fundamental to optimizing your expenses.
1. Use the System Instructions Block
A common practice is to include instructions about the desired model behavior directly in the user prompt. However, these instructions are counted as tokens with each request. By using the "system instructions block," you define the model's behavior once, avoiding the repetition of these instructions in each prompt. This significantly reduces token consumption, especially in long conversations or frequent interactions.
2. Implement Stop Sequences
Language models can generate excessively long responses or include unnecessary information. Defining "stop sequences" instructs the model to stop text generation when it encounters a specific character sequence. This prevents token consumption on irrelevant information and ensures more concise and efficient responses.
3. Adjust Media Resolution
When working with images or other types of media, resolution directly impacts the number of tokens consumed. If high resolution is not essential for the task at hand, reducing media resolution can significantly decrease token usage without compromising result quality.
4. Limit or Disable Reasoning
In some applications, it's possible to limit or disable the model's ability to "think" or generate detailed explanations. This can be useful when only the final answer is needed, reducing token consumption on unnecessary explanations. Toolzz AI allows you to configure reasoning levels for your agents, optimizing efficiency in different scenarios.
5. Utilize Context Caching
In long interactions, the model needs to maintain conversation context to generate coherent responses. Caching relevant context information can avoid information repetition in the prompt, reducing token consumption.
6. Explore TOON Notation (Token-Oriented Object Notation)
TOON is a data format designed to optimize communication with language models, minimizing the number of tokens used to represent complex information. By structuring your data in TOON, you can significantly reduce token consumption compared to traditional formats like JSON.
7. Intelligent Model Routing
Not all tasks require the most powerful and expensive language model. Implementing an intelligent routing system that directs each task to the most appropriate model can optimize costs and performance. Use lighter models for simple tasks and reserve more advanced models for complex tasks.
Want to optimize your AI costs?
Discover Toolzz AI plans8. Selective Retention
Retaining conversation history is crucial for maintaining context. However, keeping the entire history can consume many tokens. Implement a selective retention strategy, storing only the most relevant information from the history, discarding unnecessary information.
9. Define a Response Schema
By defining a specific response schema, you instruct the model to generate responses in a predefined format, reducing variability and response size. This can decrease token consumption and facilitate response processing.
10. Use Prompt Optimizers
There are tools and techniques to optimize your prompts, removing redundant information, simplifying language, and ensuring the prompt is clear and concise. Platforms like Toolzz offer advanced prompt optimization features, helping you get the most out of your language models with minimal tokens.
Optimize your prompts and reduce costs! Discover how Toolzz AI can help you maximize the efficiency of your language models.
By implementing these strategies, you can significantly reduce the costs associated with AI usage, improving the performance and scalability of your applications. Optimizing token usage is not just a matter of economy, but also of responsibility and efficiency.
With Toolzz LXP, you can create customized training for your team on AI cost optimization, ensuring everyone is aligned with best practices. Additionally, our AI Agents can automate repetitive tasks and optimize processes, freeing your team to focus on higher-value activities.
See how easy it is to create your AI
Click the arrow below to start an interactive demonstration of how to create your own AI.



















