GPU Optimization: Advances in Communications for AI
An exploration of recent innovations in GPU communication optimization, including RCCLX and Direct Data Access (DDA), and their impact on AI model training and inference performance.

GPU Optimization: Advances in Communications for AI
March 16, 2026
As Artificial Intelligence (AI) models become increasingly complex, the need to optimize communication between graphics processing units (GPUs) becomes crucial to ensure performance and scalability. Recent innovations, such as RCCLX, are paving the way for faster and more efficient communications, driving the future of AI.
The Importance of GPU Communication in AI
The efficiency of communication between GPUs is a determining factor in the training and inference of AI models. Operations such as AllReduce, AllGather, and AllToAll, which involve data exchange between GPUs, can become significant bottlenecks, limiting the overall system performance. Optimizing these operations is fundamental to accelerating the development and deployment of AI solutions.
RCCLX: A New Approach to GPU Communications
RCCLX (Remote Collective Communication Library eXtended) is an evolution of RCCL, designed to optimize communications on AMD platforms. Developed and tested internally by Meta, RCCLX offers features such as direct data access (DDA) and low-precision collectives, which provide significant performance gains compared to traditional communication libraries. It integrates seamlessly with Torchcomms, allowing developers to take advantage of optimization without needing to significantly modify existing code.
Direct Data Access (DDA): Reducing Latency
DDA is a technique that aims to reduce latency in communication operations by allowing each GPU to directly access the memory of other GPUs to perform local reduction operations. There are two DDA algorithms that optimize communication in different scenarios:
- DDA Flat: Ideal for small messages, reduces AllReduce latency from O(N) to O(1).
- DDA Tree: Suitable for slightly larger messages, reduces latency by using a tree approach to divide the operation into smaller phases.
These algorithms significantly improve performance in tasks such as large language model (LLM) inference, resulting in faster response times and a better user experience.
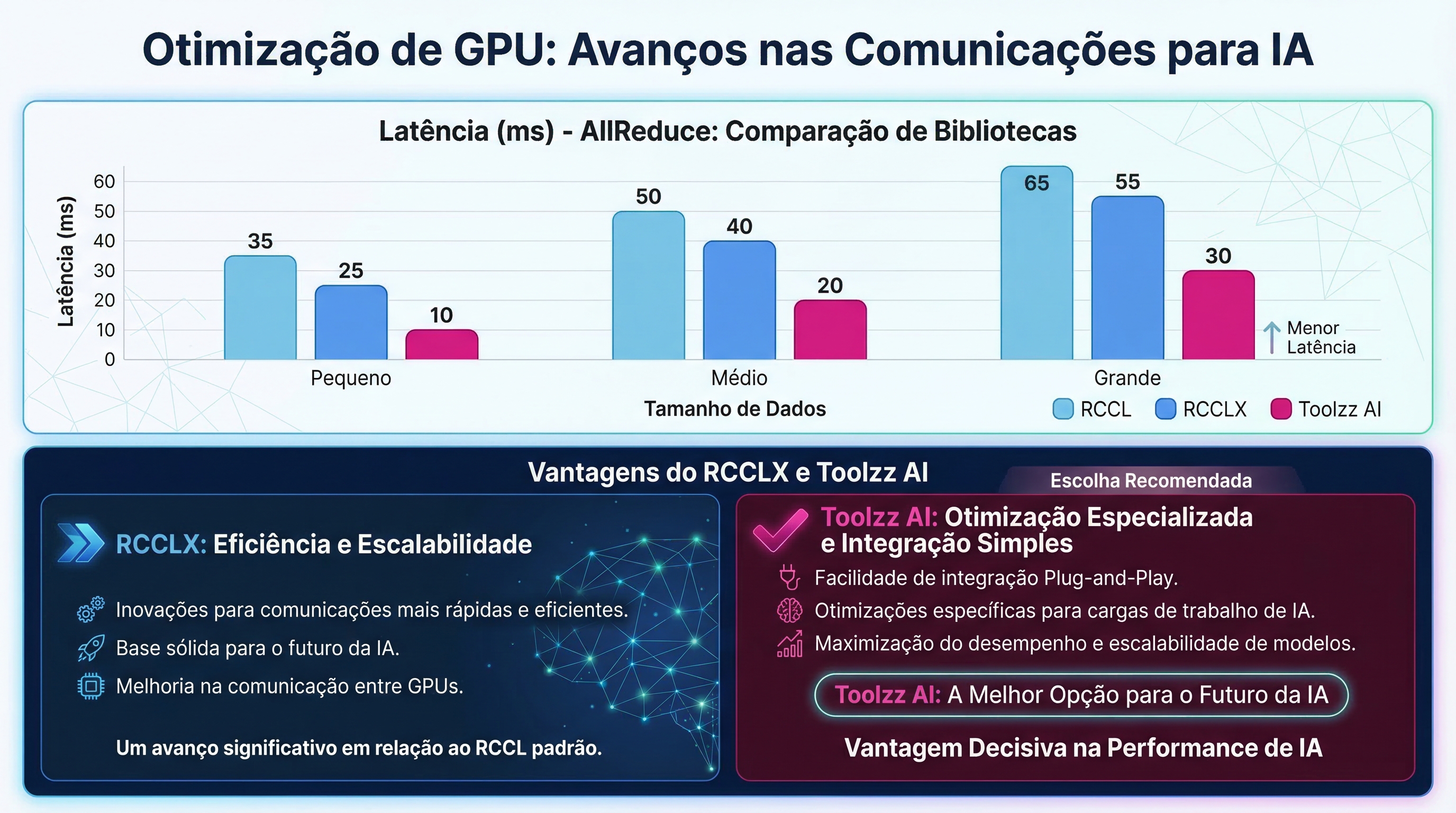
Low-Precision Collectives: Accelerating Processing
Low-precision (LP) collectives are optimized algorithms for AMD Instinct MI300/MI350 GPUs that use FP8 quantization to reduce the volume of data transferred during communication operations. This technique can result in significant improvements in scalability and resource usage, especially for large messages (≥16MB). By dynamically enabling LP collectives, users can optimize the performance of their AI models without compromising numerical accuracy.
Want to optimize your AI models?
Request a Toolzz AI demoEase of Adaptation with Toolzz AI
Toolzz AI facilitates the integration of optimized AI models for different platforms, including AMD. With Toolzz AI, you can create and deploy custom AI agents that benefit from the latest innovations in GPU communication, such as RCCLX. Our platform offers automation tools that simplify the process of deploying and managing AI models, allowing you to focus on developing innovative solutions.
Are you ready to simplify the deployment of your AI models? Discover Toolzz AI plans and pricing and find the ideal solution for your needs.
Conclusion
GPU communication optimization is a critical factor for the success of large-scale AI projects. Innovations such as RCCLX and DDA are opening new possibilities to accelerate the training and inference of AI models, enabling companies to make the most of their GPU power. By adopting solutions like Toolzz AI, companies can simplify the process of deploying and managing optimized AI models, driving innovation and gaining competitive advantages.
See how easy it is to create your AI
Click the arrow below to start an interactive demonstration of how to create your own AI.