Tokens de Retomada e IDs para Streaming LLM: Reconexão Inteligente
Descubra como os tokens de retomada e IDs de eventos garantem a continuidade do streaming LLM, evitando interrupções e otimizando custos.

15 de março de 2026
Tokens de Retomada e IDs para Streaming LLM: Reconexão Inteligente
A interrupção de uma conexão durante o streaming de respostas de modelos de linguagem (LLM) pode ser frustrante e custosa, exigindo que o processo seja reiniciado do zero. Os tokens de retomada e os IDs de último evento surgem como soluções para garantir a continuidade do streaming, permitindo que os clientes retomem exatamente de onde pararam, sem perda de dados ou necessidade de repetir solicitações. Esses mecanismos são cruciais para manter uma experiência de usuário fluida e eficiente, especialmente em aplicações que dependem de respostas longas e complexas.
Como Funcionam os Tokens de Retomada
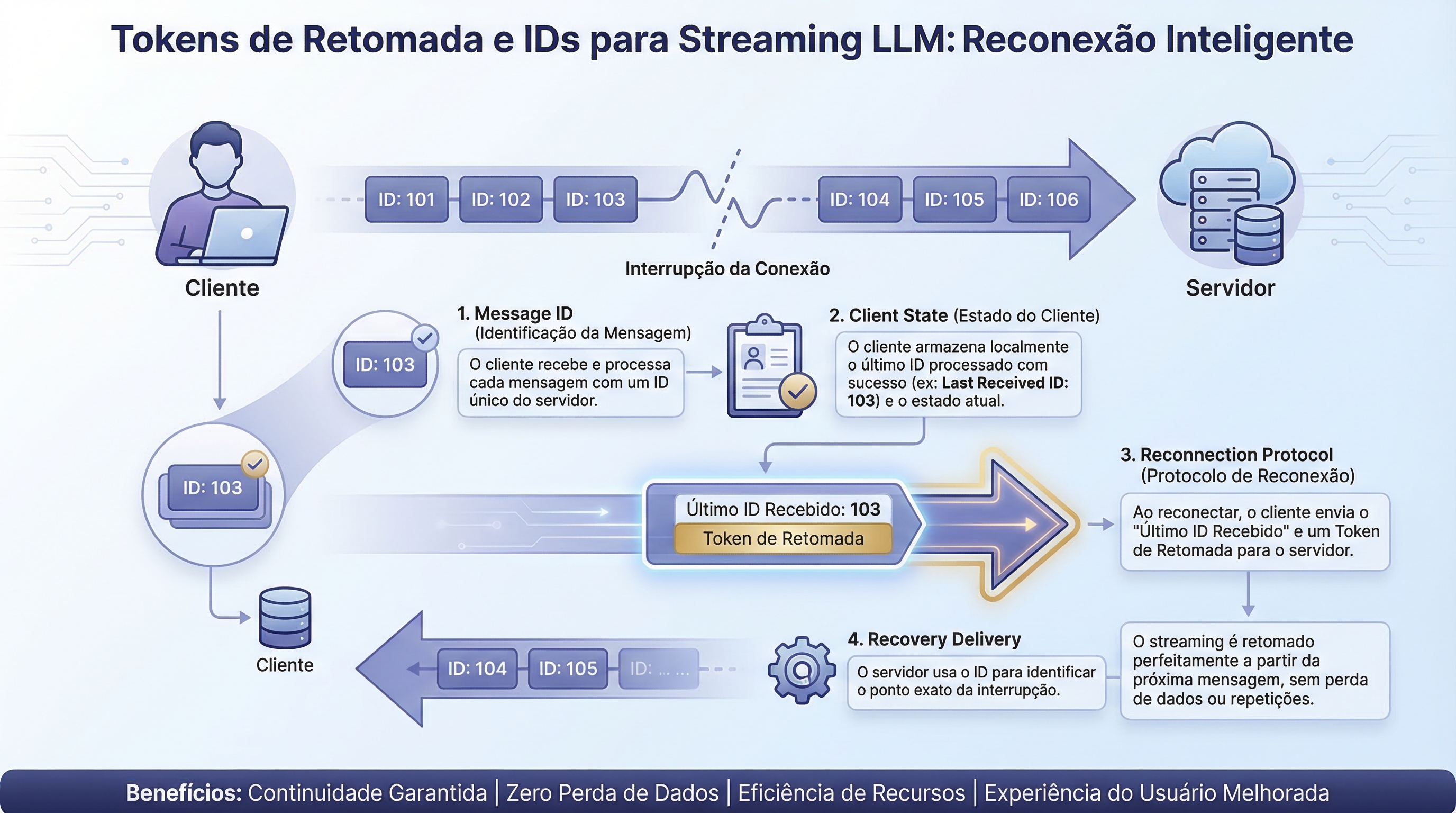
A retomada de streaming envolve quatro componentes principais:
- Identificadores de Mensagem: Cada token ou mensagem recebe um ID sequencial, aumentando monotonicamente.
- Estado do Cliente: O cliente rastreia o ID da última mensagem recebida com sucesso. Este estado precisa ser persistente, especialmente em dispositivos móveis.
- Protocolo de Reconexão: Após uma queda de conexão, o cliente apresenta o último ID recebido. O servidor responde com todas as mensagens subsequentes.
- Entrega de Recuperação: O cliente recebe as mensagens perdidas em ordem antes de retomar o streaming ao vivo, garantindo uma transição suave.
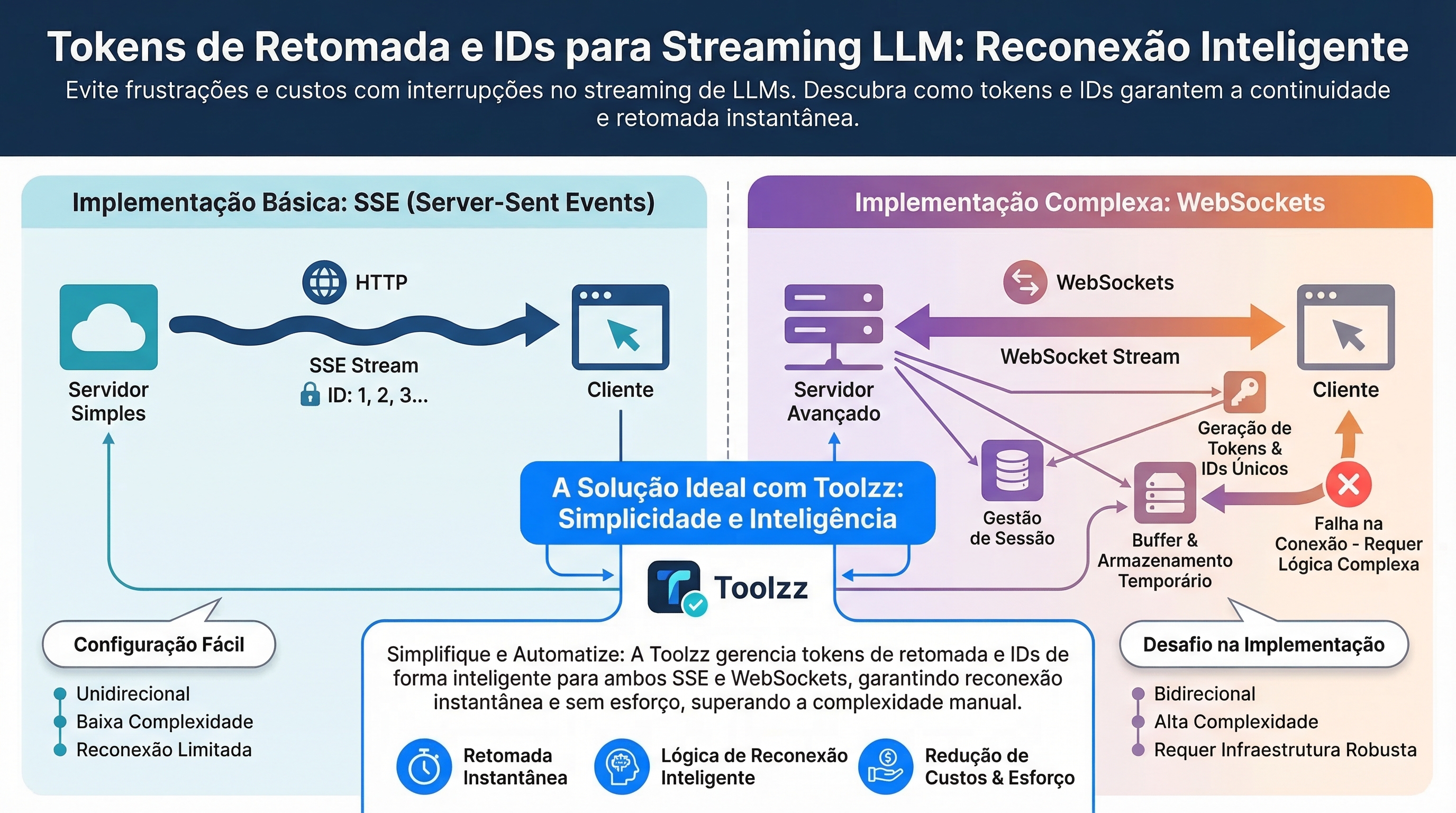
Server-Sent Events (SSE) e Last-Event-ID
Server-Sent Events (SSE) implementa a retomada nativamente. Quando uma conexão SSE é interrompida, o navegador inclui automaticamente um cabeçalho Last-Event-ID na reconexão. O servidor utiliza este ID para retomar o streaming do ponto correto. No entanto, o SSE é unidirecional e HTTP-only, o que limita sua capacidade de lidar com mensagens bidirecionais ou cenários de múltiplos dispositivos.
Retomada em WebSockets
WebSockets, ao contrário do SSE, não possuem semântica de retomada embutida. Implementar a retomada em WebSockets requer a construção de toda a lógica, incluindo:
- Geração e armazenamento de IDs de sessão.
- Atribuição sequencial de IDs de mensagem.
- Lógica do servidor para buscar sessões, reproduzir histórico e transicionar para o streaming ao vivo.
- Gerenciamento de buffer para mensagens não confirmadas.
- Lógica de limpeza para sessões expiradas.
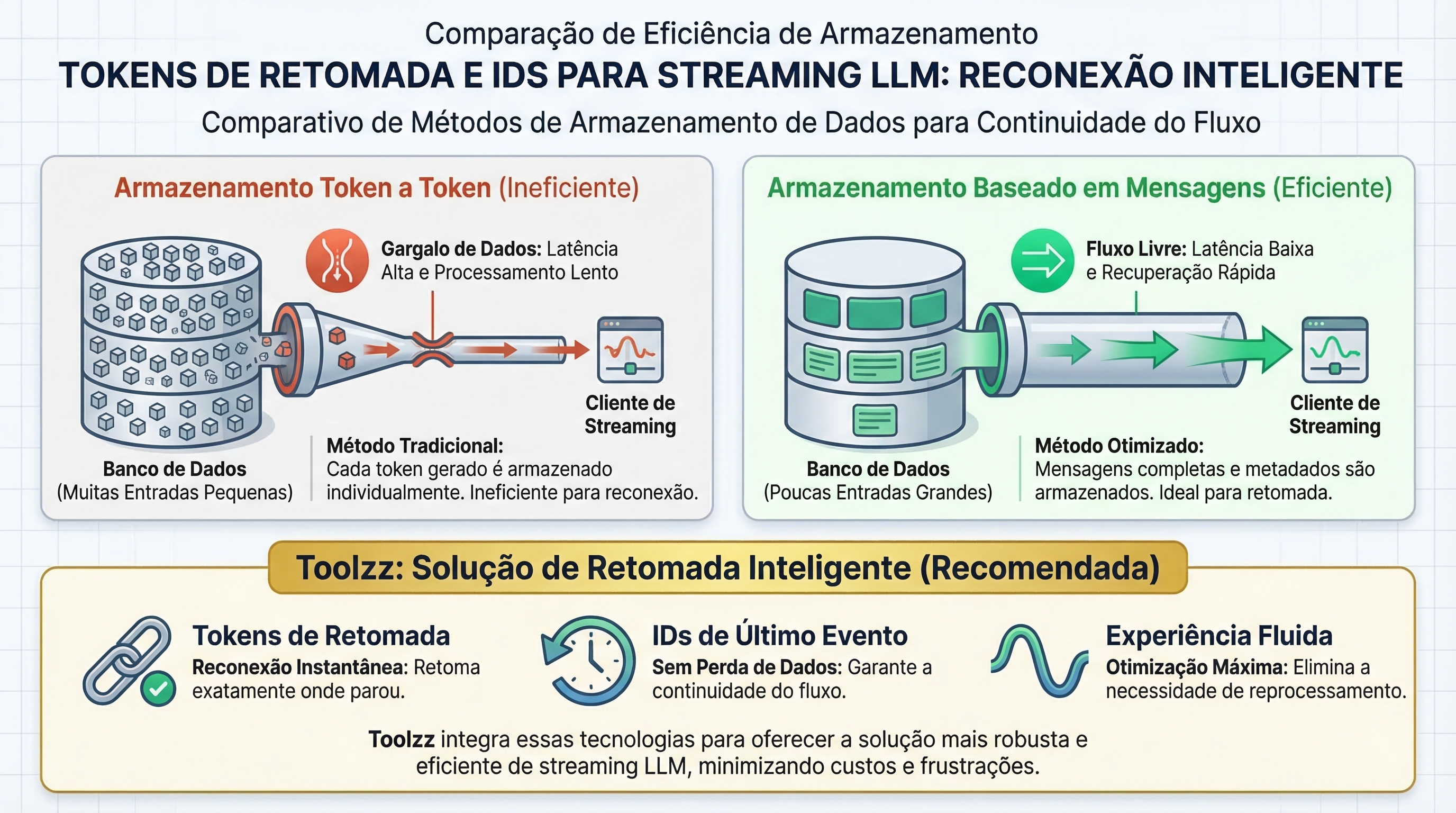
Desafios de Armazenamento e Recuperação
O armazenamento de tokens em nível granular (token por token) pode se tornar um gargalo de performance. Uma resposta de 500 palavras pode gerar 625 tokens, exigindo a recuperação de 625 registros para reconstruir a resposta. Uma abordagem mais eficiente é tratar cada resposta de IA como uma única mensagem lógica, anexando os tokens a ela. Isso reduz drasticamente o número de registros a serem gerenciados.
Está buscando otimizar o uso de LLMs na sua empresa? Conheça a Toolzz AI e descubra como podemos te ajudar.
Duplicação e Lacunas: Falhas Críticas
Duplicações ocorrem quando a conexão cai após o cliente receber uma mensagem, mas antes do servidor receber a confirmação. Na reconexão, o servidor pode reenviar a mesma mensagem. A solução é usar IDs de mensagem como chaves de deduplicação no cliente.
Lacunas ocorrem quando IDs sequenciais chegam fora de ordem ou não chegam. Sem detecção de lacunas, o cliente pode renderizar uma resposta incompleta. A detecção de lacunas requer lógica para solicitar mensagens faltantes e lidar com a impossibilidade de recuperá-las.
Implicações da Implementação Distribuída
Em uma implementação com múltiplos servidores, um cliente pode se reconectar a uma instância diferente da original. Isso exige uma estratégia para:
Roteamento de reconexões para a instância original (o que pode criar hotspots).
Armazenamento do estado da sessão em uma infraestrutura compartilhada (como Redis), acessível a todas as instâncias.
O Gap Multi-Dispositivo
A continuidade multi-dispositivo exige uma arquitetura diferente. Quando o estado reside na conexão ou na memória do servidor, a troca de dispositivos perde o contexto. A solução é desacoplar o estado das conexões, armazenando a conversa em um canal ou armazenamento persistente. Os dispositivos se inscrevem e recuperam o histórico, em vez de retomar uma conexão.
Quando a Retomada de Streaming é Essencial
A retomada de streaming é crucial em cenários como:
- Clientes móveis com frequentes handoffs de rede.
- Respostas longas, com alta probabilidade de falhas transitórias.
- Uso multi-dispositivo.
- Sistemas multi-agente, onde vários agentes publicam atualizações em um canal compartilhado.
Toolzz Voice: Garanta a Continuidade nas Interações por Voz
A implementação de tokens de retomada e IDs de eventos pode ser complexa, exigindo tempo e expertise para lidar com todas as nuances e cenários de falha. Para empresas que buscam uma solução robusta e eficiente para agentes de voz, a Toolzz Voice oferece a garantia de continuidade nas interações, mesmo em condições de rede instáveis. Com a Toolzz, você pode focar na criação de experiências de conversação de alta qualidade, sem se preocupar com os detalhes técnicos da retomada de streaming.
Além disso, a Toolzz AI oferece uma gama completa de agentes de IA personalizados para diversas necessidades, desde IA de Vendas até IA de Suporte, integrando-se perfeitamente com a Toolzz Voice e outras soluções da plataforma. Descubra como a Toolzz pode transformar a comunicação da sua empresa. Agende uma demonstração hoje mesmo.
A retomada de streaming é fundamental para garantir uma experiência de usuário consistente e confiável em aplicações que utilizam LLMs. Embora a implementação possa ser desafiadora, os benefícios em termos de retenção de usuários e redução de custos a tornam um investimento valioso. A Toolzz oferece soluções que simplificam a implementação e o gerenciamento de agentes de IA, permitindo que você se concentre no que realmente importa: a criação de valor para seus clientes.


















