P-EAGLE: Acelere a Inferência de LLMs com Decodificação Paralela
Descubra como o P-EAGLE otimiza a inferência de Large Language Models (LLMs),
P-EAGLE: Acelere a Inferência de LLMs com Decodificação Paralela
Large Language Models (LLMs) estão transformando diversas áreas, desde atendimento ao cliente até a criação de conteúdo. No entanto, a inferência – o processo de gerar respostas a partir desses modelos – pode ser um gargalo, especialmente em aplicações que exigem baixa latência. O P-EAGLE surge como uma solução inovadora, otimizando a inferência de LLMs através de uma abordagem de decodificação paralela, elevando a performance a um novo patamar.
15 de março de 2026
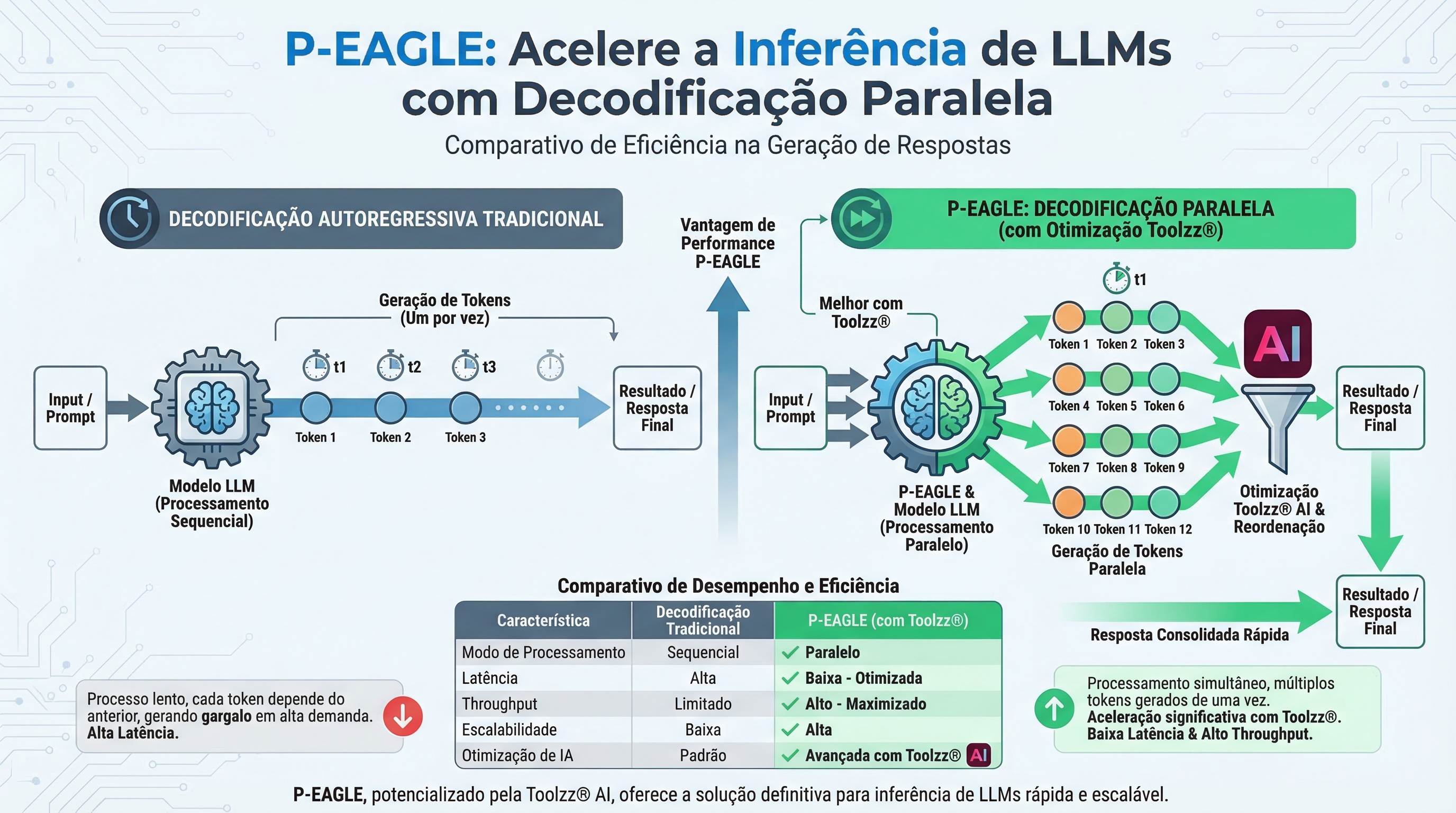

O Desafio da Inferência em LLMs
A inferência de LLMs envolve a geração sequencial de tokens (palavras ou partes de palavras). Métodos tradicionais, como a decodificação autoregressiva, geram cada token um após o outro, o que pode ser lento em modelos grandes e com sequências longas. O EAGLE, um método de decodificação especulativa, já representou um avanço significativo, mas ainda apresentava limitações com a geração autoregressiva de drafts (rascunhos), impactando a velocidade em tarefas que demandam alta especulação.
Apresentando o P-EAGLE: Decodificação Paralela para Velocidade Aprimorada
O P-EAGLE (Parallel-EAGLE) resolve o problema do EAGLE ao introduzir a geração paralela de drafts. Em vez de gerar os tokens de draft sequencialmente, o P-EAGLE gera todos os K tokens simultaneamente em uma única passagem, eliminando o gargalo da geração autoregressiva. Isso resulta em um aumento significativo na velocidade de inferência, especialmente em GPUs modernas como a NVIDIA B200, com ganhos de até 1.69x em relação ao EAGLE-3 em cenários reais.
Se você está buscando otimizar a performance dos seus LLMs, conheça a Toolzz AI e descubra como podemos ajudar.
Como Funciona o P-EAGLE?
O P-EAGLE opera em duas etapas principais:
Prefilling: O modelo principal processa o prompt e gera o token inicial, capturando os hidden states (estados ocultos) que representam o conhecimento do modelo em cada posição.
P-EAGLE Drafter: O drafter utiliza os hidden states capturados na etapa anterior para gerar K tokens de draft em paralelo. Para posições no prompt, ele combina o embedding do token com o hidden state correspondente. Para posições futuras, utiliza embeddings de máscara e hidden states compartilhados para preencher as lacunas.
Essa arquitetura permite que o P-EAGLE preveja vários tokens simultaneamente, acelerando drasticamente o processo de inferência.
Treinamento do P-EAGLE para Sequências Longas
Modelos de linguagem modernos frequentemente lidam com sequências longas, o que apresenta desafios de memória durante o treinamento do drafter. O P-EAGLE introduz um algoritmo de particionamento de sequência que divide a sequência em blocos contíguos, mantendo as dependências de atenção entre os blocos e acumulando gradientes em toda a sequência. Isso permite treinar o P-EAGLE em sequências longas sem exceder os limites de memória.

Implementando P-EAGLE com vLLM
A integração do P-EAGLE no vLLM é simplificada. Basta adicionar “parallel_drafting”: true à configuração de SpeculativeConfig. Modelos pré-treinados P-EAGLE já estão disponíveis no HuggingFace para GPT-OSS 120B, GPT-OSS 20B e Qwen3-Coder 30B, permitindo que você comece a se beneficiar das vantagens do P-EAGLE imediatamente.
Quer experimentar o poder da inferência acelerada? Solicite uma demonstração do Toolzz AI e veja como podemos otimizar seus LLMs.
O Impacto do P-EAGLE em Aplicações Práticas
O P-EAGLE tem o potencial de transformar uma variedade de aplicações que dependem de LLMs, incluindo:
- Chatbots: Respostas mais rápidas e interações mais fluidas.
- Assistentes Virtuais: Melhor capacidade de resposta e processamento de solicitações complexas.
- Geração de Conteúdo: Criação mais rápida de artigos, resumos e outros tipos de conteúdo.
- Análise de Sentimento: Processamento mais rápido de grandes volumes de texto para análise de sentimento em tempo real.
O Futuro da Inferência de LLMs com a Toolzz
A otimização da inferência de LLMs é fundamental para desbloquear todo o potencial dessas tecnologias. A Toolzz está na vanguarda dessa evolução, e o P-EAGLE representa um passo importante nessa direção. Com o Toolzz AI, você pode aproveitar o poder de LLMs otimizados, como o P-EAGLE, para criar soluções de IA personalizadas e escaláveis. Explore nossos agentes de IA e descubra como podemos ajudar você a transformar seus negócios com a inteligência artificial. Se você busca maximizar a performance e reduzir a latência em suas aplicações de LLM, a Toolzz é a sua parceira ideal. Experimente o Toolzz AI hoje mesmo e veja a diferença!
















