Reduza Custos com IA: 10 Estratégias para Otimizar o Uso de Tokens
Economize em IA otimizando o uso de tokens com estas 10

Reduza Custos com IA: 10 Estratégias para Otimizar o Uso de Tokens
17 de março de 2026
À medida que a inteligência artificial se torna cada vez mais presente em nossas aplicações, o controle de custos associados ao seu uso se torna crucial. Um dos principais componentes desses custos é o consumo de tokens, unidades de dados processadas pelos modelos de linguagem. Otimizar o uso de tokens não apenas reduz despesas, mas também melhora a performance e a escalabilidade de seus sistemas de IA.
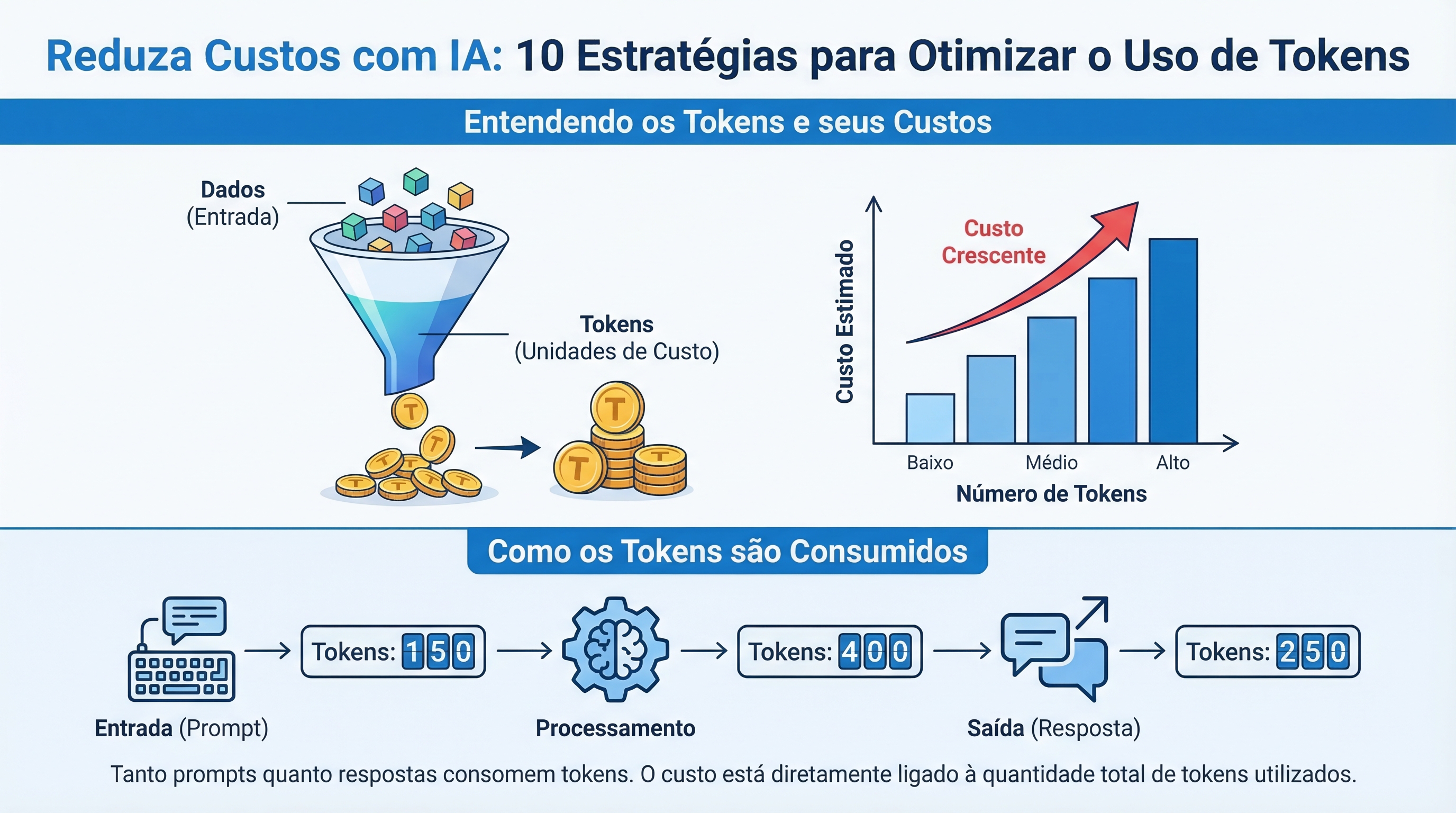
Entendendo os Tokens e seus Custos
Um token representa a menor unidade de informação que um modelo de IA processa. Tanto a entrada (prompt) quanto a saída (resposta) de um modelo consomem tokens. O custo do uso de IA está diretamente ligado à quantidade de tokens utilizados. Entender como os tokens são contados e como reduzir seu consumo é fundamental para otimizar seus gastos.
1. Use o Bloco de Instruções do Sistema
Uma prática comum é incluir instruções sobre o comportamento desejado do modelo diretamente no prompt do usuário. No entanto, essas instruções são contadas como tokens a cada requisição. Ao usar o "bloco de instruções do sistema", você define o comportamento do modelo uma única vez, evitando a repetição dessas instruções em cada prompt. Isso reduz significativamente o consumo de tokens, especialmente em conversas longas ou interações frequentes.
2. Implemente Sequências de Parada
Modelos de linguagem podem gerar respostas excessivamente longas ou incluir informações desnecessárias. Definir "sequências de parada" instrui o modelo a interromper a geração de texto ao encontrar uma determinada sequência de caracteres. Isso evita o consumo de tokens com informações irrelevantes e garante respostas mais concisas e eficientes.
3. Ajuste a Resolução de Mídia
Ao trabalhar com imagens ou outros tipos de mídia, a resolução impacta diretamente o número de tokens consumidos. Se a alta resolução não for essencial para a tarefa em questão, reduzir a resolução da mídia pode diminuir significativamente o uso de tokens, sem comprometer a qualidade do resultado.
4. Limite ou Desabilite o Pensamento
Em algumas aplicações, é possível limitar ou desabilitar a capacidade do modelo de "pensar" ou gerar explicações detalhadas. Isso pode ser útil quando apenas a resposta final é necessária, reduzindo o consumo de tokens com explicações desnecessárias. A Toolzz AI permite configurar níveis de raciocínio para seus agentes, otimizando a eficiência em diferentes cenários.
5. Utilize Cache de Contexto
Em interações longas, o modelo precisa manter o contexto da conversa para gerar respostas coerentes. Armazenar em cache as informações relevantes do contexto pode evitar a repetição de informações no prompt, reduzindo o consumo de tokens.
6. Explore a Notação TOON (Token-Oriented Object Notation)
TOON é um formato de dados projetado para otimizar a comunicação com modelos de linguagem, minimizando o número de tokens utilizados para representar informações complexas. Ao estruturar seus dados em TOON, você pode reduzir significativamente o consumo de tokens em comparação com formatos tradicionais como JSON.
7. Roteamento Inteligente de Modelos
Nem todas as tarefas exigem o modelo de linguagem mais poderoso e caro. Implementar um sistema de roteamento inteligente que direciona cada tarefa para o modelo mais adequado pode otimizar custos e performance. Utilize modelos mais leves para tarefas simples e reserve os modelos mais avançados para tarefas complexas.
Quer otimizar seus custos com IA?
Descubra os planos da Toolzz AI8. Retenção Seletiva
A retenção do histórico de conversas é crucial para manter o contexto. No entanto, manter todo o histórico pode consumir muitos tokens. Implemente uma estratégia de retenção seletiva, armazenando apenas as informações mais relevantes do histórico, descartando informações desnecessárias.
9. Defina um Esquema de Resposta
Ao definir um esquema de resposta específico, você instrui o modelo a gerar respostas em um formato predefinido, reduzindo a variabilidade e o tamanho das respostas. Isso pode diminuir o consumo de tokens e facilitar o processamento das respostas.
10. Use Otimizadores de Prompt
Existem ferramentas e técnicas para otimizar seus prompts, removendo informações redundantes, simplificando a linguagem e garantindo que o prompt seja claro e conciso. Plataformas como a Toolzz oferecem recursos avançados de otimização de prompts, ajudando você a obter o máximo de seus modelos de linguagem com o mínimo de tokens.
Otimize seus prompts e reduza custos! Descubra como a Toolzz AI pode te ajudar a maximizar a eficiência dos seus modelos de linguagem.
Ao implementar essas estratégias, você pode reduzir significativamente os custos associados ao uso de IA, melhorando a performance e a escalabilidade de suas aplicações. Otimizar o uso de tokens não é apenas uma questão de economia, mas também de responsabilidade e eficiência.
Com a Toolzz LXP, você pode criar treinamentos personalizados para sua equipe sobre otimização de custos com IA, garantindo que todos estejam alinhados com as melhores práticas. Além disso, nossos Agentes AI podem automatizar tarefas repetitivas e otimizar processos, liberando sua equipe para se concentrar em atividades de maior valor.
Veja como é fácil criar sua IA
Clique na seta abaixo para começar uma demonstração interativa de como criar sua própria IA.



















